Cache Deception Without Path Confusion
Hello readers,
Today, we’ll talk about a unique case of a cache deception vulnerability that I found in one of the Synack Red Team targets. I call this particular case of cache deception vulnerability unique because unlike the usual cache deception exploits, this exploit did not rely on path confusion.
Unlike my other blogs, I have decided to explain some of the basics in this one because the little details are fascinating!
Let’s break down the blog into smaller chunks so that we can take one bite at a time.
The Basics⌗
Before going to the specifics of the vulnerability, I would like to elaborate more on the terminologies and techniques that we will use in this blog.
Path Confusion⌗
Path confusions occur when the application is not configured properly to distinguish between different paths. In a nutshell— it is when two different paths are interpreted as the same path by the application. Similar to what happens in a hash collision.
Let’s take an example. Suppose you request the following URL:
https://kuldeep.io/account/billing
Everything is okay and you go to the billing page of your account. Now, you visit a second URL:
https://kuldeep.io/account/billing/nonexistent.js
In an ideal scenario, visiting this URL should result in a 404 Not Found because the JS file that we requested does not exist on the web server.
However, due to a misconfiguration in how the application processes paths/routes, the application takes you to the billing page of your account.
This is path confusion— two different paths interpreted as the same.
So many talks on a topic that I did not even use in my final exploit.
Web Caching⌗
Processing webpages is a resource-intensive task. When you send a request to, for example, a server running PHP, the server runs the PHP code and provides you with the response.
This is useful in cases when you are working with dynamic data like user profile information or financial information. However, you do not want the server to process requests to the homepage, or a header/footer, or a static file because as we discussed earlier, it is a resource-intensive task.
Static files might not take that many resources as compared to the application code but the server still needs to process those requests one-by-one.
This problem can be solved using web caching.
Web caching is when a front-end server caches the response and serves it to the visitors of the website without relying on the back-end server. This can be explained with the following illustration:
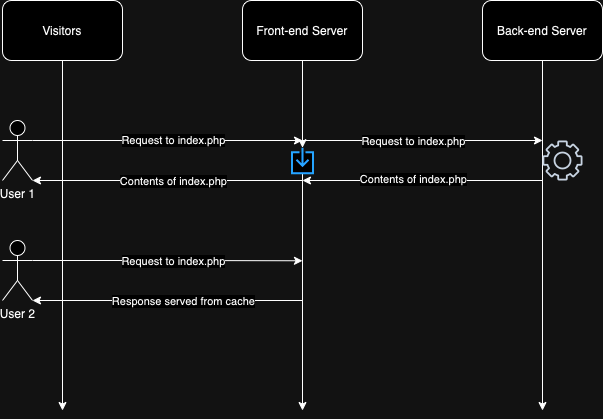
When a response is served from the cache, you will likely see the following response headers indicating this:
X-Cache: HIT
X-CDN-Cache: HIT
A HIT means that the response is served from the cache. When it is the otherwise, you will see a MISS instead of HIT.
Please note that the response header names are likely to vary.
How does the front-end server know when to cache the request? It makes use of cache keys!
Cache Keys⌗
Cache keys are a number of factors that determine whether or not the request will be cached. Usually, cache keys comprise the URL, the user agent, and the user region. Cache keys can be customized to cache based on specific conditions.
Different front-end servers have different mechanisms for configuring cache keys. Nevertheless, the basic concept stays the same.
Web Cache Deception⌗
In the Web Caching section, we saw that the front-end server can be configured to cache specific responses. This raises a question— what if we cache responses that should not be cached?
Usually, only the static resources are cached. But if we could somehow cache the responses that contain sensitive data like cookies or session identifiers or JSON Web Tokens or PII, it would be awesome or scary depending on what side you are on.
Web Cache Deception attacks occur when an attacker forces the front-end server to cache sensitive data and then retrieve it from the cache.
Discovery⌗
The very first step towards discovering a WCD vulnerability is to log in to the target application as a normal user and make notes of interesting endpoints.
What makes an endpoint interesting? Well, it highly depends on the nature of the application. For example, if it is a betting application, maybe knowing how many bets you have made might be interesting. If it is a banking application, most of the endpoints might be interesting because you do not want anyone to know your bank details. All-in-all, we can all agree that all endpoints that disclose PII are sensitive.
While doing this, make sure that the endpoints that you come across are using cookies as the authentication mechanism instead of bearer tokens. Why is this important will be covered in the exploitation section.
Once you have a vast list of interesting endpoints, you can check for path confusion misconfigurations. While doing this, check the response for cache-related headers to see if you see any cache HITs.
For this, I would suggest reading this awesome write-up by Bombon: https://bxmbn.medium.com/how-i-test-for-web-cache-vulnerabilities-tips-and-tricks-9b138da08ff9
If you see any cache HITs in the interesting endpoints, it can likely be exploited.
Why do we see cache HITs? Because front-end servers might be configured to cache JS files, CSS files, images, etc. And because we are using path confusion, the front-end server will treat it as a JS file or a CSS depending on what extension you chose. However, the backend server will treat it as a normal request because routing is misconfigured.
Exploit⌗
Once you have found that an interesting endpoint is resulting in a cache HIT, it is time to craft the exploit.
Let’s assume that we have found that https://kuldeep.io/account/billing/nonexistent.js results in a cache HIT. We have also confirmed that the web application is using cookies as the authentication mechanism. Let’s convert this to an exploit.
- Send this URL to the victim: https://kuldeep.io/account/billing/nonexistent.js
- Once the victim visits the URL from his/her authenticated session, the backend server will respond with the billing information. The front-end server will cache the response because it believes that the response is coming from a JS file and JS files should be cached.
- The attacker will retrieve the billing information by visiting the https://kuldeep.io/account/billing/nonexistent.js URL. Because the response has been cached, the attacker will receive a cached copy from the front-end server. This cached copy includes all the billing information of the victim.
Here, if the application used bearer tokens, we cannot exploit this by simply sending the URL to the victim. It would require an XSS to exploit. And if you already have an XSS, there is no point exploiting WCD.
Limitations⌗
- WCD will not work if the user isn’t logged in.
- It will not work if the application is using bearer tokens as the authentication mechanism.
- In some configurations, the cache will only be served if you are in the same region as the victim.
- If you accidentally visit the URL that you sent to the victim, the victim will receive the cached copy instead of you.
- Even if you get the victim to cache his/her response, the cache may get invalidated after a few seconds or minutes.
Now that we have covered the basics, let’s move to the WCD vulnerability that I found in one of the Synack targets.
WCD On A Synack Target⌗
Initial Observations⌗
I was onboarded to a target where some SRTs had already submitted some vulnerabilities like information disclosures and a few access controls.
I connected to the target and started traversing the application like a normal user. Wherever possible, I was checking for SQL injections. While doing this, I noticed the static files were served from a GraphQL API. This was unusual.
I checked what API the application used for dynamic data. To my surprise, it used the same GraphQL API for both, static and dynamic data.
To retrieve static content, the application used a URL like this:
/ui-gateway/v1/graphql?query=query{somequery{someattribute}}&reqIdentifier=someReqIdentifier
In the response header, I noticed that the responses were being cached. I came to this conclusion by seeing the following headers:
X-Served-By: cache-iad-somethingrandom-IAD
X-Cache: HIT
X-Cache-Hits: 1
To retrieve dynamic content, the application sent a POST request to the GraphQL API. Unlike the GET requests, the POST requests did not get cached.
I thought about converting the POST requests to GET requests to see if they got cached. For this, I used an interesting query that is as follows:
query {
userDetails {
authStatus {
authType
email
firstName
lastName
roles
userId
userLogin
birthDate
isUnderAgeUser
}
geoLocation
}
}
This query returns the PII of the currently logged-in user.
I converted it to a GET request. The final URL looked like this:
/ui-gateway/v1/graphql?query=query{userDetails{authStatus{authType email firstName lastName roles userId userLogin birthDate isUnderAgeUser}geoLocation}}
Excited to see the results, I visited the URL from the browser and checked if the response was cached. Sadly, it was not cached. I could not see any cache HITs.
This made me wonder, how are requests to static queries being cached while dynamic queries aren’t. I sent both of the requests to Burp Suite comparer to see if any special headers determined if the request was cached.
While doing this, I found a crucial parameter that I had overlooked. The reqIdentifier parameter.
The reqIdentifier parameter determined if the request would be cached or not. It was in the cache key. If two requests have the same reqIdentifier parameter, they would be treated as the same requests by the front-end server.
Crafting The Exploit⌗
Now that I had a way to get sensitive information cached, I just had to craft an exploit. A malicious URL that I would send to the victim to get his/her PII cached.
I used the previous userDetails query that I had used in a GET request and appended the reqIdentifier parameter. Sending this parameter made sure that the request will be cached.
The final exploit URL looked like this:
/ui-gateway/v1/graphql?query=query{userDetails{authStatus{authType email firstName lastName roles userId userLogin birthDate isUnderAgeUser}geoLocation}}&reqIdentifier=exploitMe
For a proof-of-concept, I opened two browser windows. One was with a logged-in session (victim session), and the other was an incognito window (attacker session).
I opened the exploit URL from the logged-in session. This made sure that the PII was cached by the front-end server. By visiting the URL just once, the front-end server cached the response.
I then opened the same URL from the incognito window and I was greeted with the victim account’s PII. This way, without any sort of authentication, I was able to access a victim account’s confidential details.
I created an easy-to-follow PoC for this exploit and sent it to Synack. And they happily accepted the vulnerability.
Thank you for reading. If you have any queries or doubts, feel free to ping me on X, Instagram, or LinkedIn.
References And Further Reading⌗
- https://portswigger.net/daily-swig/path-confusion-web-cache-deception-threatens-user-information-online
- https://portswigger.net/research/practical-web-cache-poisoning
- https://bxmbn.medium.com/chaining-cache-deception-poisoning-250ec69774c8
- https://developers.cloudflare.com/cache/cache-security/cache-deception-armor/
- https://www.varnish-software.com/glossary/what-is-web-caching/
Happy Hacking! :)